
1. 서론
일반적으로 소스코드 불법 복제 또는 개작 행위는 유사 또는 동일한 기능을 불법으로 쉽게 구현하기 위한 방법으로 사용되므로, 동일․유사 기능에 해당하는 소스파일끼리 파일비교쌍을 만들어 비교하는 것이 효과적이다.
마찬가지로, 실행코드의 경우에도 동일․유사 기능에 해당하는 역어셈블 코드끼리 비교하는 것이 효과적이다. 다만, 상위수준 언어로 개발된 원 소스코드의 경우에는 특정 기능에 해당하는 소스코드 분석 및 추출이 용이한 반면 컴파일된 형태의 실행코드는 해당부분의 분석 및 추출이 어렵다. 실행코드의 유사도를 효과적으로 비교하기 위한 여러가지 비교 항목을 분류해 보았다.
2. 관련 기술
소스코드의 실행문과 비실행문을 대상으로 이루어지는 복제여부는 라인이나 토큰(Token) 단위의 비교를 통해서 이루어지기 때문에 감정대상 소프트웨어의 규모에 따라 분석을 위한 많은 시간과 노력이 요구된다. 일반적으로 소스코드의 비교분석은 표절탐지 도구나 감정 도구, 또는 버전관리 도구 등을 사용하여 동일 및 유사 파일을 도출하고, 비교결과의 신뢰성을 제공하기 위해 육안 확인(Eye check)을 병행․수반 한다.
코드블록의 위치변경, 변수 및 함수 이름의 변경과 같은 소스코드의 조작에도 원본과 동일 또는 유사한 소스코드를 탐지할 수 있어야 한다. 또한 인접라인비교 알고리즘을 사용하여 소스코드의 구조적인 특징을 정확히 분석해야 한다.

3. 실행코드 유사도 비교
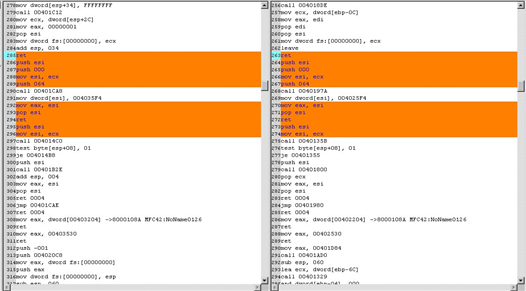
역어셈블된 어셈블리어 코드는 OP 코드와 OPRAND로 구성되며 OPRAND에는 레지스터, 직접주소, 간접주소, 상수 값 등이 온다. 특히 매우 유사한 소스코드를 컴파일한 후 역어셈블을 수행한 경우나, 동일산 소스코드에 다른 컴파일 옵션을 주어 컴파일한 후 역어셈블한 경우에도 직접주소 및 간접주소값의 경우 주소 할당방식이나 text 세그먼트, data 세그먼트 등 코드의 위치변경에 따라 OPRAND의 주소값이 달라진다.
따라서, 소스코드에 대해 작은 수정이나 컴파일 옵션의 차이에 의해서도 변동이 많은 OPRAND 부분에 의해 역컴파일된 코드간의 유사도 비교결과는 비교적 낮게 나온다.
동일한 소스코드에 컴파일 옵션을 달리하여 컴파일 한 후 역어셈블을 수행한 코드에 대해 유사도 비교한 결과가 상당히 낮게 나옴을 알 수 있다. 이때 외부 영향에 변동성이 많은 OPRAND 부분을 제거하고 OP 코드만을 대상으로 유사도를 비교한 결과 비교적 높은 유사도를 갖는다.
물론, 어셈블리어 구조의 단순성에 의해 우연히 일치할 수 있는 경우가 많이 발생할 수 있지만, 유사성 분석시 인접블럭 임계치를 높게 설정하는 경우 우연히 일치할 수 있는 부분에 의한 과탐지를 감소시킬 수 있다.
그리고, 일정수준의 인접블럭 임계치에서 일련의 OP 코드가 연속적으로 일치한다면 이는 동일한 소스코드를 컴파일한 확률이 높다고 볼 수 있다.
또한 우연히 일치할 수 있거나 개발툴에 의해 자동으로 생성될 수 있는 연속 코드블럭에 대한 다양한 패턴을 수집하여 유사하다고 표시된 부분에 대한 패턴검색을 통해 과탐지(false positive) 또는 오탐지(false negative) 부분을 필터링시킬 수 있다.
컴파일 옵션에서 속도를 우선으로 최적화하는 경우와 파일크기를 최적화 하는 경우가 있다. 그림에서 빨간색 부분은 NOP이고, 검은색은 JUMP, 노란색은 함수영역이다. 파일크기 최적화시 불필요한 NOP 부분등이 대폭 축소된 것을 확인할 수 있다.




'개발 & 보안' 카테고리의 다른 글
| AI 개발 패러다임의 진화 :: Prompt → context → Harness Engineering by. 엘에스웨어 고춘화 (0) | 2026.04.24 |
|---|---|
| RSAC 2026 :: AI 에이전트 시대의 사이버 보안 동향과 생존 전략 by. 엘에스웨어 이경하 (0) | 2026.04.02 |
| 개발자 역할별 생성형 AI 개발 활용 전략 by. 엘에스웨어 신창권 (0) | 2026.03.18 |
| 보안자산과 취약점 관리: IT자산을 넘어선 접근 by. 엘에스웨어 이경하 (0) | 2026.02.10 |
| ISMS-P 심사에서 자주 지적되는 보안 항목과 대응 전략 by 엘에스웨어 양원석 (0) | 2025.11.12 |