
최근 거대 언어 모델(LLM)과 고도화된 AI 시스템이 산업 전반에 도입되면서, 방대한 크기의 모델을 효율적으로 운영하기 위한 '모델 경량화' 기술이 주목받고 있습니다. 그중에서도 지식 증류(Knowledge Distillation)는 무거운 AI 모델의 성능을 유지하면서 크기를 줄이는 핵심 기술로 자리 잡았습니다. 하지만 이러한 혁신적인 기술이 기업의 핵심 자산인 'AI 모델'을 탈취하는 데 악용될 수 있다는 사실을 아시나요?
이번 아티클에서는 지식증류의 기본 개념과 올바른 활용법을 짚어보고, 이를 악용한 보안 위협(공격)과 엘에스웨어의 관점에서 바라본 대응 방안까지 심도 있게 다루어 보겠습니다.
1. 지식 증류 기술이란?
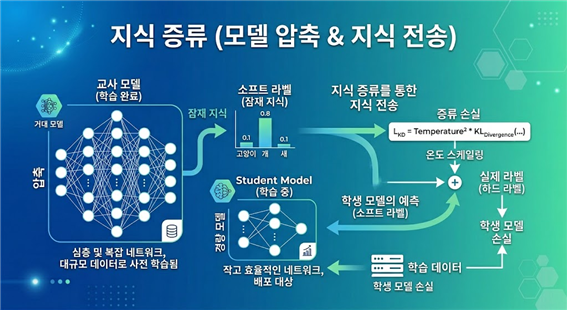
지식 증류 기술은 크고 복잡한 모델(Teacher Model, 교사 모델)이 학습한 지식을 작고 단순한 모델(Student Model, 학생 모델)에 전달하여, 학생 모델이 교사 모델과 유사한 성능을 낼 수 있도록 학습시키는 모델 압축 기법입니다.
일반적으로 AI 모델이 예측을 수행할 때, 정답인 클래스뿐만 아니라 오답인 클래스에 대해서도 미세한 확률값을 출력합니다. 예를 들어, 개 이미지를 보고 '개(90%), 고양이(9%), 자동차(1%)'라고 판단하는 식입니다. 여기서 정답 외의 오답들이 가진 미세한 확률 분포를 '암묵적 지식(Dark Knowledge)'이라고 부릅니다.
지식증류는 학생 모델이 단순히 정답만을 학습하는 것이 아니라, 교사 모델이 생성한 이 세밀한 확률 분포(Soft Label)까지 모방하도록 유도합니다. 마치 뛰어난 스승이 학생에게 정답만 알려주는 것이 아니라, 문제를 푸는 노하우와 오답을 피하는 직관까지 전수하는 것과 같습니다.
2. 지식 증류 기술의 올바른 활용
지식 증류는 본래 AI의 효율성과 활용도를 극대화하기 위해 개발된 긍정적인 기술입니다. 주요 활용 방법은 다음과 같습니다.
- 모델 경량화 및 엣지 디바이스 배포 : 수십~수백 GB에 달하는 대형 모델은 스마트폰, IoT 기기 등 컴퓨팅 자원이 제한된 환경에서 구동하기 어렵습니다. 지식증류를 통해 성능 저하를 최소화하면서 모델 크기와 추론 시간을 획기적으로 줄여 온디바이스 AI를 구현할 수 있습니다.
- 학습 성능 및 일반화 능력 향상 : 처음부터 작은 모델을 독립적으로 학습시키는 것보다, 잘 학습된 큰 모델을 교사로 삼아 지식증류로 학습시킬 때 작은 모델의 최종 정확도와 보이지 않는 데이터에 대한 일반화 성능이 훨씬 높아집니다.
- 앙상블 모델의 단일화 : 여러 개의 모델을 합쳐 결론을 내는 앙상블 기법은 성능이 뛰어나지만 연산량이 많습니다. 여러 교사 모델의 예측 결과를 하나의 학생 모델에 증류하면, 단일 모델로도 앙상블에 준하는 강력한 성능을 낼 수 있습니다.
3. 지식 증류 공격 방법 및 사례
지식증류의 놀라운 '지식 복제' 능력은 공격자의 손에 들어가면 심각한 보안 위협인 모델 추출 및 복제 공격이 될 수 있습니다.
[공격 메커니즘]
공격자는 기업이 막대한 비용을 들여 개발한 상용 AI 모델(블랙박스 API)의 내부 가중치나 코드를 직접 해킹할 필요가 없습니다. 대신 API에 무수히 많은 질의를 보내고, 반환되는 결과(확률 분포나 텍스트)를 수집합니다. 이렇게 수집된 데이터를 바탕으로 자신의 로컬 환경에서 학생 모델을 학습시키면, 상용 모델과 유사한 성능을 내는 복제 모델을 공짜로 얻게 됩니다.

[주요 사례]
- LLM 복제 사례 (Alpaca 등): 오픈AI의 GPT-3.5나 GPT-4와 같은 강력한 상용 모델에 수만 개의 프롬프트를 입력하고, 그 출력 결과를 모아 오픈소스 모델(LLaMA 등)을 미세조정(Fine-tuning)하는 방식이 널리 사용되었습니다. 이는 학술적 목적(Stanford Alpaca 등)으로 시작되었으나, 기업의 지식재산권(IP) 침해 논란을 불러일으켰습니다.※ Stanford CRFM, "Alpaca: A Strong, Replicable Instruction-Following Model," https://crfm.stanford.edu/2023/03/13/alpaca.html (2023)
- 학습 데이터 오염 및 복제 의혹 (DeepSeek): 중국의 AI 기업 딥시크(DeepSeek)는 코딩에 특화된 DeepSeek-Coder 모델 학습 데이터 중 상당 부분이 오픈AI의 GPT-4를 이용해 생성된 것이라는 의혹을 받았습니다. 이는 경쟁사의 API 출력물을 자사 모델 학습 데이터로 활용하는, 일종의 간접적 지식증류 방식의 모델 추출 공격에 대한 우려를 낳았습니다.※ BusinessInsider, "Major coding model accused of being GPT-4 clone," https://www.businessinsider.com/major-coding-model-deepseek-coder-v2-accused-being-gpt-4-clone-2024-6
- 금융/의료 AI 탈취 (시나리오): 경쟁사가 특정 기업의 유료 신용평가 API나 의료 진단 API를 지속적으로 호출하여 얻은 예측 확률값으로 자체 모델을 증류해 내는 산업 스파이 형태의 공격이 발생할 수 있습니다.※ IEEE Xplore, "Model Extraction Attacks and Defenses on Machine Learning-based Classification Models," (General threat scenario discussed in security research literature)
4. 지식 증류 공격 대응방안
엘에스웨어와 같은 보안 및 컴플라이언스 전문 기업의 관점에서, AI 자산을 보호하기 위해 다음과 같은 다각적인 방어 체계가 필요합니다.
- 문맥을 이해하는 AI 가드레일을 통한 쿼리 차단 : 가장 적극적인 방어는 공격자의 악의적인 질문 자체를 입구에서 차단하는 것입니다. 단순히 특정 키워드를 필터링하는 수준을 넘어, LLM 기반의 고도화된 프롬프트 의미 분석 기술을 활용하여 입력된 질의의 문맥적 의도를 파악해야 합니다. 이를 통해 모델의 지식을 체계적으로 탈취하려는 시도(예: 데이터 공간을 촘촘하게 탐색하는 질문 패턴 등)를 실시간으로 탐지하고 차단하는 AI 가드레일을 구축할 수 있습니다.

- 세션 기반 트래픽 분석을 통한 이상징후 탐지 : 모델 추출 공격은 필연적으로 단기간에 방대한 양의 쿼리를 발생시킵니다. 단순히 일정 시간당 요청 횟수를 제한하는 것뿐만 아니라, 동일 사용자 또는 IP에 대한 세션 단위의 종합적인 트래픽 분석이 필요합니다. 세션 내에서 발생하는 비정상적인 쿼리 빈도, 데이터 전송량, 질의의 다양성 부족 등 이상징후를 다각도로 분석하여, 인간 사용자가 아닌 자동화된 공격 도구에 의한 접근을 정밀하게 가려내고 차단해야 합니다.
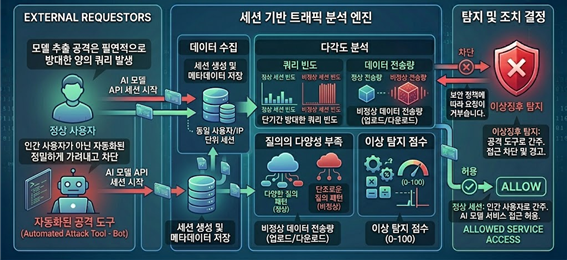
- 노이즈 및 워터마크 삽입을 통한 무단 재학습 방지 : 공격자가 데이터를 일부 수집하더라도 이를 학습 데이터로 활용하지 못하게 하거나, 활용 사실을 추적할 수 있도록 출력값을 가공하는 기술입니다. 노이즈 삽입 방안은 모델이 반환하는 예측 확률값에 사용자에게는 영향을 주지 않는 미세한 동적 노이즈를 추가하여, 공격자가 깨끗한 암묵적 지식을 증류해 내는 것을 어렵게 만듭니다. 워터마킹 방안은 LLM의 텍스트 출력물에 눈에 보이지 않거나 알아차리기 힘든 특정 패턴을 삽입합니다. 누군가 지식증류로 모델을 훔쳐 복제 모델을 만들 경우, 복제 모델 역시 해당 워터마크 패턴을 학습하게 되어 사후 검증을 통해 무단 탈취 및 지식재산권 침해 사실을 법적으로 증명할 수 있는 결정적 근거로 활용할 수 있습니다.

5. 향후 지식 증류 관련 연구 방향
지식증류는 단순한 모델 압축을 넘어, 성능 최적화와 보안이라는 두 마리 토끼를 잡아야 하는 새로운 연구 국면에 접어들었습니다.
- 보안 인식형 지식증류 (Security-aware KD): 모델을 경량화하기 위해 지식증류를 적극적으로 수행하되, 그 과정에서 원본 모델이 가진 민감 정보(개인정보 등)나 핵심 IP가 학생 모델로 전이되지 않도록 통제하는 '안전한 증류' 연구가 활발해질 것입니다.
- 추론 과정의 증류 (Chain-of-Thought Distillation): LLM 시대에 맞추어, 단순히 결과값만 모방하는 것을 넘어 AI가 정답을 도출하는 '논리적 추론 과정' 자체를 작은 모델에 주입하는 연구가 핵심 트렌드로 부상하고 있습니다.
- 연합 학습과 지식증류의 결합 (Federated Distillation): 데이터 프라이버시가 중요해짐에 따라, 원본 데이터를 서버로 모으지 않고 각 사용자 기기에서 지식증류를 통해 추출된 '모델의 요약된 지식'만을 공유하여 전체 시스템을 고도화하는 보안 지향적 AI 연구가 가속화될 전망입니다.
마치며
지식증류는 AI의 대중화를 이끄는 마법 같은 기술이지만, 기업의 핵심 자산을 노리는 양날의 검이 될 수도 있습니다. 앞으로 AI 기술을 도입하는 기업은 모델의 성능 향상뿐만 아니라, '우리의 AI 자산을 어떻게 보호할 것인가'에 대한 보안적 통찰을 반드시 함께 갖추어야 할 것입니다.



'R&D' 카테고리의 다른 글
| 탐지를 넘어 신뢰로: 설명 가능한 AI(XAI)가 바꾸는 사이버 보안의 미래 by 엘에스웨어 김현수 (0) | 2025.10.02 |
|---|